NVIDIA CUDA là gì? Nền tảng biến GPU thành siêu máy tính AI
Đăng bởi PVYSTORE2026-04-14 01:00:32👁 141 lượt xem
Bài viết này do AI tạo ra, có thể mắc sai sót.
Mở bài
Nếu bạn từng thắc mắc tại sao GPU lại là trái tim của cách mạng AI, thì câu trả lời nằm ở một nền tảng tên là CUDA. Ra đời năm 2007, CUDA biến GPU Nvidia từ một con chip chuyên render game thành bộ xử lý đa năng — mở đường cho deep learning, machine learning và mọi ứng dụng tính toán song song ngày nay.
Video đang nói gì?
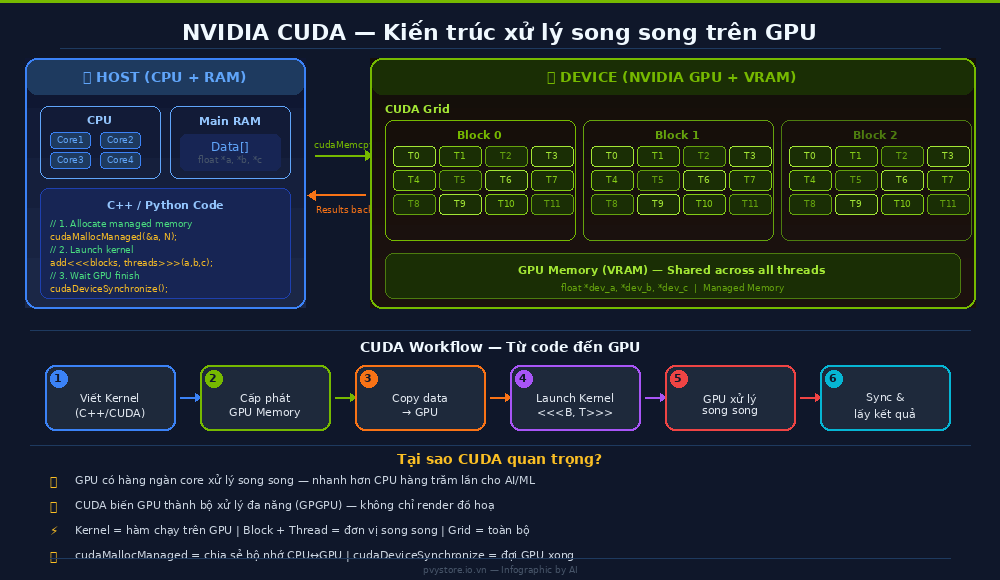
CUDA (Compute Unified Device Architecture) là nền tảng tính toán song song của Nvidia ra đời năm 2007, dựa trên nghiên cứu của Ian Buck và John Nichols.
GPU có hàng ngàn core (RTX 490 có trên 16.000 core) so với CPU chỉ có vài chục core — GPU sinh ra để xử lý hàng triệu phép tính giống nhau cùng lúc.
CUDA Kernel là hàm C++ chạy trên GPU. Lập trình viên viết kernel, cấp phát bộ nhớ GPU, rồi launch kernel với cú pháp đặc trưng <<<blocks, threads>>>.
Managed Memory (cudaMallocManaged) cho phép CPU và GPU chia sẻ bộ nhớ mà không cần copy tay — đơn giản hoá quy trình phát triển.
cudaDeviceSynchronize tạm dừng CPU chờ GPU tính xong, đảm bảo dữ liệu chính xác trước khi tiếp tục. CUDA là nền tảng cốt lõi xây dựng mọi hệ thống AI phức tạp hiện nay.
Giải thích bản chất
1) CUDA là gì và tại sao nó quan trọng?
CUDA là nền tảng lập trình song song do Nvidia phát triển, cho phép GPU — vốn chỉ chuyên render đồ hoạ — thực hiện các tác vụ tính toán tổng quát (GPGPU). Trước CUDA, muốn dùng GPU tính toán phải "hack" qua shader pipeline rất phức tạp. CUDA cung cấp API đơn giản bằng C/C++, biến GPU thành "siêu máy tính song song" mà developer nào cũng có thể dùng.
Kết quả: CUDA đã mở đường cho cuộc cách mạng deep learning. Mọi framework AI lớn (PyTorch, TensorFlow) đều chạy trên CUDA. Không có CUDA, ChatGPT và hàng loạt mô hình AI sẽ không tồn tại như ngày nay.
2) Kiến trúc CUDA: Grid, Block, Thread
Khi bạn launch một CUDA kernel, GPU tổ chức công việc theo hệ thống phân cấp:
Thread = đơn vị xử lý nhỏ nhất, mỗi thread chạy cùng một hàm kernel nhưng trên dữ liệu khác nhau.
Cú pháp kernel<<<numBlocks, threadsPerBlock>>>(args) cho phép bạn kiểm soát mức độ song song. GPU sẽ tự phân phối hàng ngàn thread lên các core vật lý để chạy đồng thời.
3) Luồng dữ liệu: CPU ↔ GPU
Quy trình chuẩn của một ứng dụng CUDA:
Cấp phát bộ nhớ trên GPU (cudaMalloc hoặc cudaMallocManaged).
Copy dữ liệu từ RAM (host) sang VRAM (device) — hoặc dùng Managed Memory để tự động.
Launch kernel — GPU bắt đầu xử lý song song.
Gọi cudaDeviceSynchronize() — CPU đợi GPU xong.
Lấy kết quả từ VRAM về RAM.
Với Managed Memory, bước 2 và 5 được xử lý tự động — code ngắn gọn hơn rất nhiều.
Sơ đồ minh hoạ
Áp dụng thực tế
Huấn luyện AI/ML: PyTorch, TensorFlow, JAX đều dựa trên CUDA để train model trên GPU — nhanh gấp hàng trăm lần so với CPU.
Xử lý ảnh/video: FFmpeg + NVENC, Adobe Premiere, DaVinci Resolve dùng CUDA để encode/decode video realtime.
Khoa học & mô phỏng: mô phỏng vật lý, dự báo thời tiết, docking phân tử trong nghiên cứu thuốc — tất cả dùng CUDA.
Cryptocurrency: mining Ethereum (trước đây) chạy thuần CUDA trên GPU Nvidia.
Lập trình viên: nếu bạn có GPU Nvidia, cài CUDA Toolkit + viết kernel C++ là có thể bắt đầu thử nghiệm tính toán song song.
Inference AI local: chạy LLM (llama.cpp, Ollama) trên máy cá nhân — đều cần CUDA để tận dụng GPU.
Kết luận
CUDA không chỉ là một công cụ lập trình — nó là nền tảng đã thay đổi cả ngành công nghiệp AI. Bằng cách biến GPU thành bộ xử lý đa năng với hàng ngàn thread song song, CUDA cho phép chúng ta train những mô hình AI khổng lồ mà CPU đơn thuần không bao giờ làm nổi. Nắm vững CUDA = nắm vững chìa khoá của kỷ nguyên AI.