Bài viết này do AI tạo ra, có thể mắc sai sót.
V4 có hai phiên bản: V4-Pro (mạnh, chuyên coding và agent phức tạp) và V4-Flash (nhanh, rẻ, phù hợp ứng dụng phổ thông). Cả hai đều mã nguồn mở, ai cũng tải về dùng và chỉnh sửa được.
Về hiệu năng, theo benchmark của DeepSeek: V4-Pro ngang ngửa Claude Opus 4.6, GPT-5.4 và Gemini 3.1 trên các bài test coding, toán và STEM. So với các model mã nguồn mở khác như Qwen-3.5 hay GLM-5.1, V4 vượt trội toàn diện.
Về giá: V4-Pro chỉ $1.74/triệu token đầu vào và $3.48/triệu token đầu ra — rẻ hơn nhiều lần so với OpenAI và Anthropic. V4-Flash còn rẻ hơn nữa: khoảng $0.14 input / $0.28 output cho mỗi triệu token, biến nó thành một trong những model top-tier rẻ nhất thế giới.
Khảo sát nội bộ của DeepSeek với 85 developer có kinh nghiệm cho thấy hơn 90% chọn V4-Pro trong top model ưu tiên cho coding. Model cũng được tối ưu sẵn cho các framework agent phổ biến như Claude Code, OpenClaw và CodeBuddy.
V4 xử lý được 1 triệu token cùng lúc — đủ chứa toàn bộ bộ ba Chúa Nhẫn + The Hobbit. Nhưng điểm đáng chú ý không phải con số, mà là cách V4 làm được điều đó.
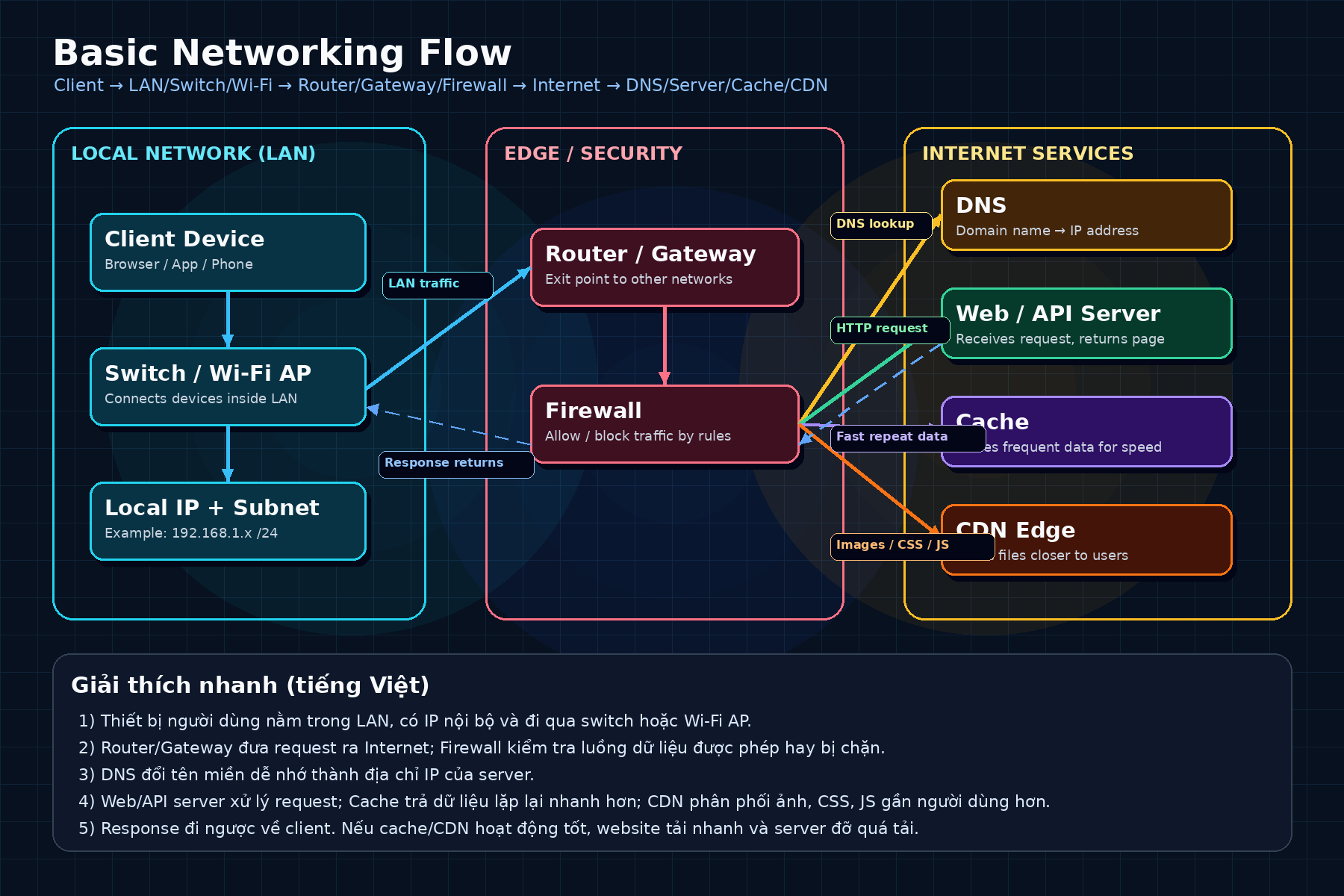
Thông thường, khi prompt dài hơn, model phải so sánh mọi phần text với nhau (attention mechanism), tốn rất nhiều tài nguyên. V4 giải quyết bằng cách nén thông tin cũ và chỉ tập trung vào phần quan trọng nhất cho câu trả lời hiện tại, trong khi vẫn giữ nguyên chi tiết gần nhất.
Kết quả thực tế:
Điều này mở ra khả năng xây dựng AI assistant đọc được toàn bộ codebase, hoặc agent nghiên cứu phân tích kho tài liệu khổng lồ mà không bị "quên" nội dung phía trước — với chi phí thấp hơn rất nhiều.
V4 là model đầu tiên của DeepSeek được tối ưu cho chip Huawei Ascend — chip AI nội địa Trung Quốc. DeepSeek không cho Nvidia và AMD truy cập sớm vào V4 (điều thường thấy trong ngành), mà chỉ chia sẻ với các hãng chip Trung Quốc.
Huawei xác nhận dòng Ascend 950 sẽ hỗ trợ chạy V4. Điều này có nghĩa ai muốn tự host V4 có thể dùng chip Huawei thay vì phải tìm mua GPU Nvidia (vốn bị Mỹ cấm xuất khẩu sang Trung Quốc từ 2022).
Tuy nhiên, bài viết của MIT Technology Review chỉ ra rằng DeepSeek chưa hoàn toàn thoát Nvidia: chip Huawei hiện chủ yếu dùng cho inference (chạy model phục vụ người dùng), còn phần training (huấn luyện) có thể vẫn dùng GPU Nvidia. Giáo sư Lưu Chí Viễn (Đại học Thanh Hoa) nhận định V4 mới chỉ chuyển một phần training sang chip nội địa.
DeepSeek cho biết giá V4-Pro có thể giảm đáng kể khi Huawei Ascend 950 được sản xuất hàng loạt vào nửa cuối năm nay. Nếu thành công, đây sẽ là tín hiệu sớm cho thấy Trung Quốc đang xây dựng được hạ tầng AI song song, không phụ thuộc hoàn toàn vào công nghệ Mỹ.
V4 có thể không gây chấn động như R1 hồi đầu 2025, nhưng nó quan trọng ở ba điểm: (1) model mã nguồn mở giờ đã ngang hàng model đóng của Big Tech với giá rẻ kỷ lục, (2) kỹ thuật nén attention mới có thể thay đổi cách xây dựng AI agent xử lý tài liệu dài, và (3) việc tối ưu cho chip Huawei là bước đi địa chính trị — không chỉ là chuyện kỹ thuật. Với developer, V4 mở ra lựa chọn mạnh mẽ, rẻ và tự do tuỳ chỉnh. Với ngành AI, đây là thêm bằng chứng rằng cuộc đua model mã nguồn mở đang nóng hơn bao giờ hết.